Understanding Edge Database Architecture: Reducing Global Data Latency
Are centralized cloud databases bottlenecking your international user experience? Discover Edge Database architecture. Learn how to distribute data closest to your global users.
Understanding Edge Database Architecture: Reducing Global Data Latency
Deploying your application frontend code to a global serverless network ensures that your HTML and static assets render in milliseconds for users anywhere in the world. However, if your application requires fetching user data from a single, centralized relational database located in Virginia or Frankfurt, your global performance targets collapse.
The Geographical Latency Trap: While your user interface initializes instantly from a local edge node, every dynamic database query is forced to travel across continents, passing through multiple network routing hops before returning to the device. This introduces high latency, degrades user experiences, and increases connection time-out risks.
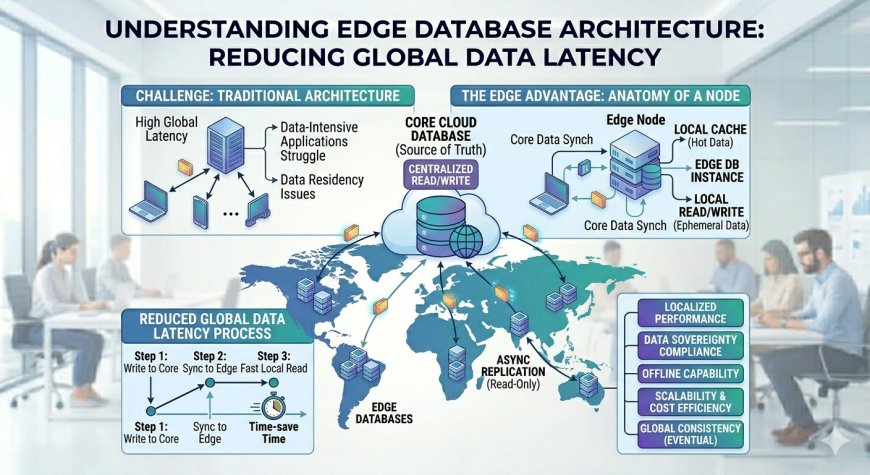
Edge database architecture completely redefines this limitation. By decentralizing your data storage and bringing read and write operations closer to the logical boundary of the user, this modern paradigm eliminates the geographical distance bottleneck.
The Core Problem: The Centralized State Bottleneck
Traditional hosting environments rely on a centralized relational database instance to maintain absolute data consistency and prevent concurrent update conflicts.
The Structural Constraint: Relational database engines operate under strict transactional guarantees. When an application server in Tokyo needs to read or write a record into a database instance situated in Ireland, the connection incurs an inescapable physical network delay caused by the speed of light through fiber-optic cables.
Furthermore, relying on a single, centralized database node creates a single point of failure risk. If that specific cloud datacenter suffers an infrastructure blackout or a network partition event, your entire global digital platform goes dark instantly.
The Architecture: The Globally Distributed Read Pool
An edge database infrastructure separates your monolithic data system into a synchronized, distributed network topology. It places compute-ready data caches directly inside the regional datacenters that experience your highest user traffic.
A modern edge data infrastructure manages read and write operations through three distinct layout layers:
-
The Primary Write Instance: A centralized database cluster that acts as the absolute authority for state changes, handling complex write operations, schema updates, and strict transaction logging.
-
The Regional Read Replica Network: A globally distributed matrix of lightweight database nodes that continuously stream identical read-only copies of your primary data records in near real-time.
-
The Connection Routing Layer: An automated middleware proxy that analyzes incoming database queries, serving read requests from the closest local node while transparently routing write calls back to the primary instance.
Quick Contrast: Centralized Database Hosting vs. Edge Database Architecture
| Operational Metric | Centralized Database Hosting Setup | Edge Database Architecture Matrix |
| Global Read Latency | High (Proportional to the user's distance) | Ultra-low (Typically under 15ms globally) |
| Network Failure Impact | Complete platform downtime for all users | Localized degradation (Other regions stay online) |
| Data Replication Model | Single local nodes or manual backup clones | Continuous, low-latency cross-region streaming |
| Infrastructure Overhead | High scaling maintenance and connection caps | Serverless abstraction with automated scale-to-zero |
| Data Consistency Scope | Immediate (All updates write directly to one node) | Eventual consistency across regional read nodes |
How to Implement an Edge Database Infrastructure
Transitioning your enterprise backend into a globally distributed edge data layout requires a deliberate separation of your read and write database execution streams.
A Critical Data Management Rule: Shifting to an edge database architecture requires your development team to accommodate the principles of eventual consistency. Because it takes a few milliseconds for a write operation to replicate from your primary instance out to your global read replicas, there is a tiny time window where a user might read stale data immediately after saving an update. Your frontend interfaces must be built to handle this using optimistic UI updates or temporary client-side state locks to ensure a seamless user experience.