How to Set Up a Highly Available Web Architecture: A Step-by-Step Hosting Guide
Learn how to design and host a highly available web application. This comprehensive infrastructure tutorial covers load balancing, replication, and failover automation.
How to Set Up a Highly Available Web Architecture: A Step-by-Step Hosting Guide
In the early stages of a web project, hosting your entire application on a single virtual private server is completely acceptable. However, as your user base grows, relying on a single instance turns into a massive operational vulnerability. If that specific cloud node experiences a hardware failure, an operating system crash, or an unexpected traffic spike, your entire platform drops offline instantly.
True high availability means building an infrastructure that can tolerate the loss of any single component without interrupting the user experience. Achieving this level of reliability requires moving away from monolithic server configurations and transitioning toward a fully redundant, decoupled hosting environment.
This technical tutorial walks you through the structural blueprint needed to eliminate single points of failure and deploy a self-healing web infrastructure.
The Core Problem: The Single Point of Failure Vulnerability
Monolithic hosting structures place your web routing logic, application execution environment, and relational databases inside the same isolated server boundary.
The Cascading Failure Threat: When a single instance handles all infrastructure responsibilities, resource exhaustion in one domain immediately destroys the others. For example, if a background application process locks up the CPU, the web server loses its ability to accept new network requests, resulting in widespread timeout errors for all active visitors.
Furthermore, centralized hosting setups prevent zero-downtime maintenance operations. Updating your database engine or upgrading your application dependencies forces you to take the entire platform offline, directly harming your service-level availability metrics.
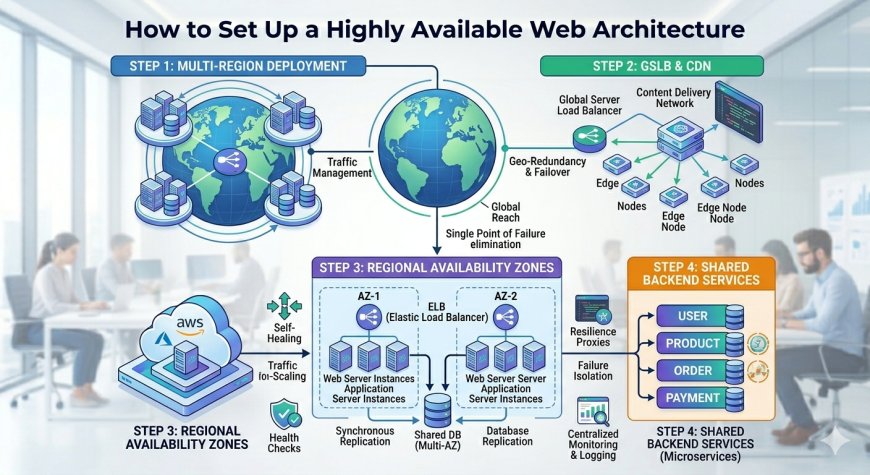
The Architecture: The High Availability Topology
A fault-tolerant hosting setup ensures that every critical resource is duplicated and monitored continuously. If an active component breaks down, traffic is automatically re-routed to a healthy node in real time.
A resilient high-availability infrastructure distributes operational weight across three distinct layers:
-
The Global Load Balancer: The public entry point for your infrastructure. It intercepts all incoming traffic, decrypts SSL certificates, and distributes network packets evenly across multiple downstream application servers.
-
The Stateless Application Pool: A cluster of independent web servers running identical copies of your application code. Because these servers store no user data locally, they can be created or destroyed instantly based on real-time traffic demands.
-
The Replicated Database Layer: A decoupled data storage cluster that separates write operations from read requests, ensuring that database records remain permanently available even during an unexpected node failure.
Quick Contrast: Monolithic Hosting vs. High Availability Architecture
| Operational Metric | Monolithic Hosting Setup | High Availability Architecture |
| Component Redundancy | None (Single point of failure exists) | Full (All layers contain redundant backup nodes) |
| Maintenance Workflows | Requires planned downtime windows | Fully supported zero-downtime rolling updates |
| Data Replication Scope | Local storage backups (Risk of data loss) | Real-time continuous replication across zones |
| Scaling Flexibility | Vertical upgrades (Requires server restarts) | Horizontal scaling (Add nodes with zero disruption) |
| Traffic Spike Behavior | Server resource saturation and crashes | Traffic distributes uniformly across the server pool |
How to Deploy a Highly Available Hosting Infrastructure
Migrating your web platform into a resilient, multi-node environment requires a systematic configuration sequence across your network and server layers.
A Critical Infrastructure Rule: High availability architectures must be validated using deliberate failure testing. Simply configuring redundant nodes is not enough to guarantee uptime. You must routinely simulate infrastructure stress by manually terminating active application servers and database nodes during off-peak hours. Documenting that your load balancers and database clusters automatically detect failures and route traffic seamlessly is the only way to ensure true platform resilience.