Understanding GitOps Infrastructure: The Modern DevOps Guide
Are manual server deployments breaking your production environments? Discover GitOps architecture. Learn how to manage infrastructure declaratively using Git as the source of truth.
Understanding GitOps Infrastructure: The Modern DevOps Guide
In the early days of cloud computing, infrastructure configuration was a highly manual process. System administrators logged into cloud consoles, clicked buttons to provision virtual machines, manually edited configuration files over SSH, and ran local bash scripts to deploy software updates.
While this approach works for small, isolated projects, it becomes a massive operational bottleneck for modern distributed applications. Manual provisioning introduces configuration drift, where live production servers slowly deviate from local staging setups. When a server crashes or a deployment fails, reproducing the exact infrastructure state becomes an error-prone guessing game.
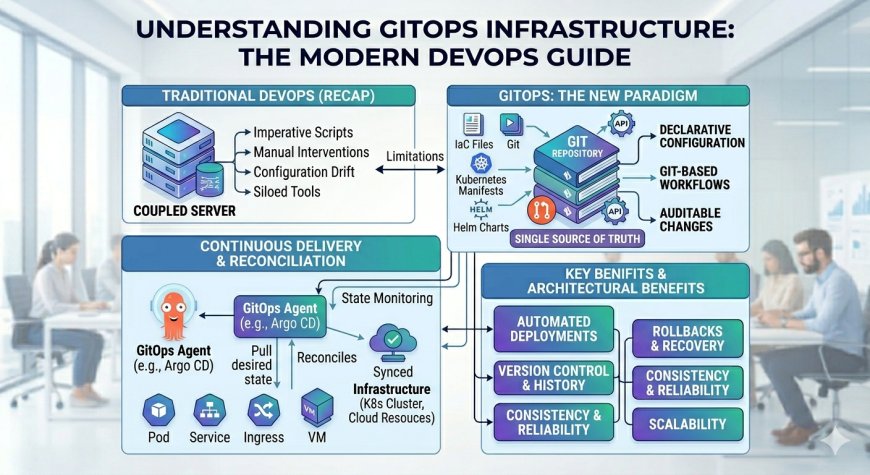
GitOps architecture completely resolves this operational vulnerability. By using Git repositories as the absolute single source of truth for infrastructure definitions, this paradigm brings software development best practices directly to cloud operations.
The Core Problem: The Configuration Drift Vulnerability
Traditional infrastructure management patterns rely on push-based deployment mechanisms. A developer or a continuous integration (CI) pipeline runs an execution script that pushes infrastructure changes out to a target hosting server or Kubernetes cluster.
The Structural Fragility: If an engineer manually alters a security firewall setting or tweaks an environment variable directly inside the live cloud console to fix an immediate emergency, that change goes undocumented. The local code files no longer match the live environment state, leading to silent production inconsistencies that break subsequent automated deployments.
Furthermore, push-based pipelines require granting heavy administrative write access to your external CI tools. If a malicious actor compromises your testing pipeline, they gain direct, unrestricted access to modify your live hosting environments and databases.
The Architecture: The Declarative Reconciliation Loop
A GitOps infrastructure completely eliminates push-based security risks and configuration drift. The architecture relies on an internal pull-based model that constantly monitors, audits, and corrects the live operational state.
A modern GitOps infrastructure architecture manages state synchronization through three distinct layers:
-
The Declarative Git Repository: The version-controlled storage environment containing configuration files that explicitly define exactly how the live infrastructure should look, rather than how to build it.
-
The Automated Reconciler Engine: A highly specialized agent (such as ArgoCD or Flux) running natively inside the isolated hosting environment that continuously monitors the Git repository.
-
The Live Managed Environment: The active cloud infrastructure or container cluster that executes the live software workload.
Quick Contrast: Traditional Infrastructure As Code vs. GitOps Architecture
| Operational Metric | Traditional Push-Based IaC Stack | Pull-Based GitOps Architecture |
| Source of Truth Location | Separated (Split between code and live state) | Absolute (Git repository dictates live environment) |
| Configuration Drift Handling | Undetected until the next manual deployment runs | Automatically corrected in minutes via active loops |
| Pipeline Access Rights | High (External CI tools hold cluster keys) | None (Internal agent pulls code securely from Git) |
| Rollback Complexity | High (Requires executing custom roll-back code) | Low (Reverting a single Git commit self-heals the app) |
| Audit Log Transparency | Weak (Relies on tracking scattered cloud logs) | Strong (Full visibility via Git commit histories) |
How to Deploy a Resilient GitOps Infrastructure
Transitioning your hosting operations into an automated, declarative GitOps model requires establishing clear separation lines between your software code and your infrastructure configuration properties.
A Critical Infrastructure Security Rule: Transitioning to a GitOps architecture forces your organization to change how it manages production access permissions. Once the reconciliation engine is active, your engineers must stop modifying live servers directly via command terminals or web dashboards. Every single modification—whether it is a simple environment variable update or an massive database scaling operation—must undergo a formal Git pull request and code review process. This model transforms security auditing from a reactive investigation into a transparent, pre-approved workflow.